Migrating Transiter from Python to Go
October 22, 2022
Transiter is a backend web service that subscribes to transit data feeds and provides an HTTP API for querying the data (e.g., “when are the next trains at Times Square?"). Transiter was originally written in Python, but over the course of the last year I rewrote it in Go. This article is my contribution to the “porting X from Python to Go” genre, which is admittedly well-trodden, but I hope it’s interesting nonetheless.
Transiter’s problem with Python
There are a bunch of generic reasons to port software from Python to a language like Go: runtime performance, faster development because of the stricter type system, and a potentially simpler deployment story. These were all highly relevant for Transiter, but the core reason for the rewrite was something quite different.
Fundamentally, Transiter has to do two things. It has a background process that periodically downloads new data from transit agencies and updates its internal database.
Separately, it runs a HTTP server that listens for incoming requests and responds accordingly using the database. There are some interactions between these two parts. For example, the API allows administrators to install new transit systems and the background process must be notified so that it starts downloading the corresponding data feeds. The HTTP API also exposes Prometheus metrics which, amongst other things, includes data about the background process itself.
It seems to me that in Python it is inherently hard to do two things in one executable. It is easy to write a single threaded Python program that does some periodic work. It is also easy to write a Python program that exports an HTTP API (using Flask, say). But doing both, and communicating between the two parts, seems to be non-trivial. My understanding is that you have to get into the process-forking game for the two parts to be running in the same program. If you get this right, I’m still not sure if communicating between them is any easier than just using HTTP.
Because of this problem with Python, Transiter eventually evolved to have a complex, multi-executable architecture. At the time of the migration, Transiter required 6 executables to run:
- A Postgres database.
- A Python executable that ran schema migrations and then exited.
- An HTTP API executable built using Flask.
- A single-threaded Python “scheduler” executable that triggered feed updates and placed them on a task queue using the Celery library.
- A Celery worker pool for running these feed updates and also handling asynchronous HTTP requests.
- A Rabbitmq instance as the underlying message queue for Celery.
To be fair, I think there was some non-essential complexity here.
I think using Celery for performing feed updates and running asynchronous HTTP updates was potentially overkill.
The schema updater could probably have been folded into the scheduler.
Also, to be clear, when deploying Transiter, having 6 executables is actually fine.
Once the correct Docker compose file has been written,
running the whole system is still a simple docker-compose up.
Still, I encountered two pain points maintaining this architecture.
First, any feature that needed to touch multiple executables was tricky to implement and required some fragile inter-process communication. The support I added for Prometheus metrics epitomises this. The metrics were stored in-memory in the scheduler executable. To allow the metrics to be scrapped, I added some custom proxying code to the API executable that forwarded the metrics requests to the scheduler’s single-threaded HTTP handler. A lot of the actual metrics data originated in the Celery cluster, and this data was provided back to the scheduler using a HTTP callback after feed updates finished. It was all very ad hoc and very fragile.
Second, running Transiter without using Docker (say when debugging end-to-end test failures) was really tedious.
How Go solves the problem
The main reason I wanted to rewrite Transiter in Go was that I knew that all of the multi-executable complexity would disappear. The Postgres database is still around of course, but all of the other functionality for Transiter is now contained in a single Go binary. This binary runs the schema migrations on start-up. It then spins up one goroutine for the feed update scheduler. It runs the various APIs on other goroutines. Any feed update or asynchronous API calls are handled in their own goroutines. Communication between all these parts is trivial because they are all in the same binary and Go has great concurrency primitives (e.g., mutexes and channels, depending on what you’re doing).
Other benefits of the migration (expected and unexpected)
The type system
I knew going into the migration that writing Transiter in a strongly typed language would be nice, but I was surprised by just how nice it was.
At the start of the project I decided to use sqlc for the database interactions, and protobuf/gRPC for the API. Transiter is meant to be used as an HTTP API, but I used gRPC as a convenient way to make the API strongly typed itself and to have a single source of truth for the structure of the API responses. The combination of sqlc and gRPC made implementing the API really easy. It’s basically mapping between strongly typed database types (generated by sqlc) and strongly typed API responses (generated by gRPC) and IDE prompts do most of the work.
Multiple APIs
Speaking of APIs, another problem in the Python version of Transiter was distinguishing between “public” endpoints that are visible to the internet, and “admin” endpoints that need to be locked down (such as the “delete this transit system” endpoint). My ad hoc solution to the problem was to check for a special HTTP header in the admin endpoints and refuse requests if the header wasn’t set. The reverse proxy configuration would then ensure requests from the internet did not provide this magic header, and so the admin endpoints could only be called from within the machine running Transiter.
Early in the Go migration I realised there was an alternative elegant solution to this: just have two distinct APIs. When launching Transiter, the two APIs are bound to different ports. The reverse proxy configuration then only allows internet traffic to reach the public port.
This approach would have been possible in Python too by adding another (seventh!) executable that exported the admin endpoints only. But, again, being able to do multiple things in one Go executable made this solution almost zero cost.
Performance
It seems the rough rule of thumb for Python to Go migrations is that programs speed up by 2-10x. Anecdotally this is what I observed. The heaviest endpoint for Transiter takes about 200ms in the Python code, and now takes 40-50ms in the Go code. (I had intended to make this scientific and run proper benchmarks, but honestly this a spare-time project and I’m not motivated to really prove the point.)
It’s worth remembering that slow code has two costs. The first cost is latency of the application. The second cost is the CPU time to run the slow code. A 200ms endpoint means a user has to wait for 200ms for a response and the server has to pay 200ms of CPU time to generate the response. (I am of course simplifying here and there is some IO time too, etc.)
The new Go code is an order of magnitude more efficient than the Python code. When I turned down the Python version of Transiter, the CPU usage on my 4 vCPU DigitalOcean VM went from about 70% to 20%:
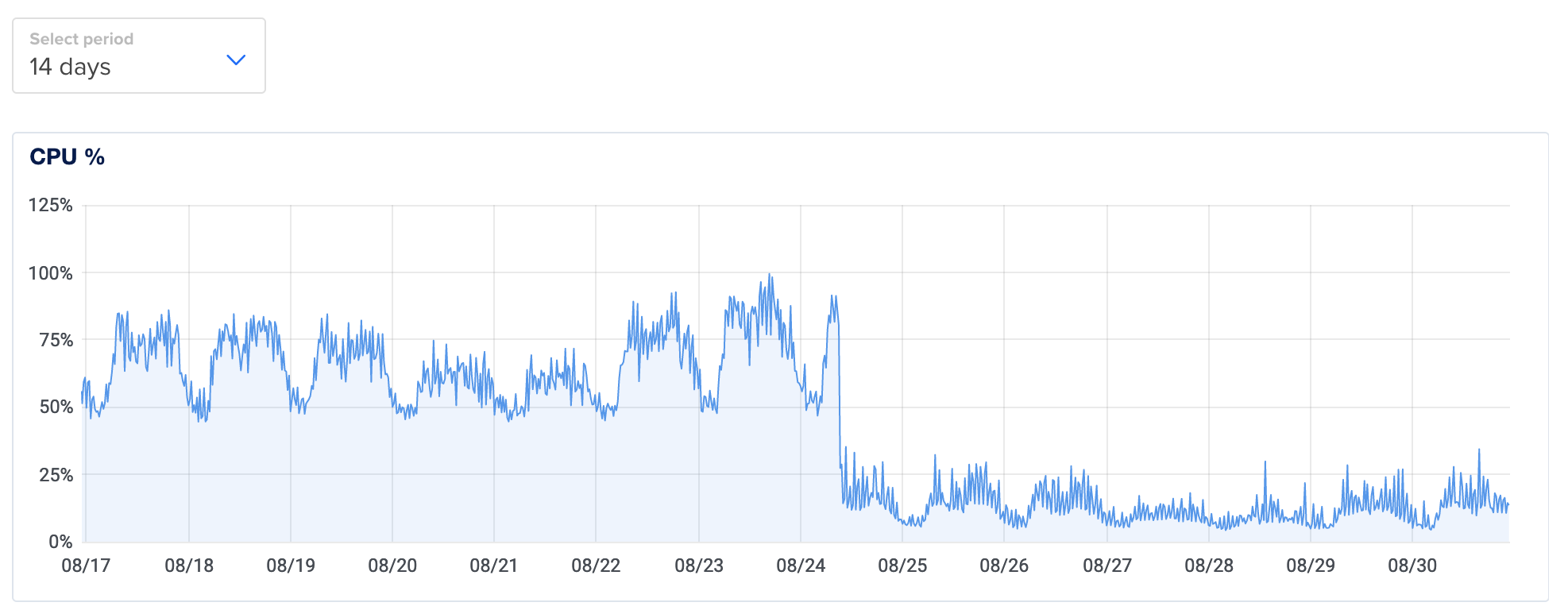
This VM is running the new functionally equivalent Go version, as well as a bunch of other services too.
(For those interested about the periodicity of the graph: most of the CPU was being used for the feed update process, and the cost of that was proportional to the size of the data being ingested. The CPU usage peaks during the day when there are lots of trains running in New York’s subway system, and goes down at night. There is also noticeably less CPU consumed on the weekend (August 20 and 21) because there are fewer trains. Keep in mind that the horizontal axis is GMT, which New York is 5 hours behind.)
A final note of caution
I want to close out by noting that rewrite reports, like this one, have an inherent bias to them. I maintained the Python version of Transiter for nearly 5 years and of course became intimately aware of all of its pain points. The Go version of Transiter has been around less than a year, mostly in development mode and not in maintenance mode. Necessarily, it is easier for me to think of the negatives of the Python version just because I worked with it so long.
Also, some of the benefits of the migration didn’t come from the language change itself, but just because it was the second time I wrote the software. For example, the Go version of Transiter has a true resource oriented REST API which I think is much easier to reason about. If Transiter v2 had been written in Python, I would have made this improvement anyway.
Overall, though, I’m happy with the migration, and feeling confident that I’ll be able to maintain the new version of Transiter easily enough for at least a decade.